


Decision support systems and the (justified?) limited utilization of AI-based prediction tools in healthcare

Decision support systems (DSS) and AI-based prediction / improvement tools have been presented in the past years as one of the biggest hopes to remedy an inefficient, burnt-out health system. To some extent it is a bit like sex in high school. Everyone is talking about it, everyone thinks others are doing it but only a few actually are doing it.
The pandemic was supposed to be a transformative event with pressing shortage in healthcare workforce vs. surging demand and many challenges / tasks that were fairly conquered by AI in other industries (prioritization, on-demand / flexible resource allocation). But within the ‘PR forest’ and tens-of-thousands of COVID related prediction models, only two got (expedited) FDA approval (Clew and Dascena).
Moreover, Nature recently published a meta-analysis of all X-Ray / CT-based prediction models related to COVID, and among 2,212 published models found that not even one is ready for clinical use. NONE.
The mismatch between the COVID opportunity and the reality, only strengthened the notion that there is still a gap (and thus opportunities) before AI-based clinical and operational decision support will become an integral part of workflow in healthcare. In this post, I’ll try to name some of the reasons for this situation and suggest a couple of methods to overcome them.
What is actually DSS

Any model development effort (should) start(s) with asking a fundamental question – what is the outcome it is trying to impact (e.g., acute kidney failure development), utilizing which intervention (e.g., specialist receiving real time alerts in their smartphones and changing medication regimen) and for which population (ICU patients). Based on the answers to these initial questions the right model should be selected and suitable data - size, characteristics, type (text, audio, image, video; phenomics, omics, etc.) to support it.
Each of these aspects can vary, as following:
1. General framework
Outcome - Clinical (improve diagnosis, drug selection, clinical management), Semi-clinical (triage, prioritization, scheduling), Operational (improve prior authrization, cost containment). , RPA or any other processes that aimed at replacing repetitive human task do not count as decision support tools (i.e. don’t help in making a decision)
Target population – patient level (“personalize medicine”) vs. sub-groups (per risk) vs. population health.
Timing of intervention – “Reactive vs. Proactive” (both are important)
Past - Flag a missing diagnosis or intervention - patient is receiving a wrong dosage of medication (descriptive)
Present - Alert a problem happening now - patient with large vessel occlusion in his brain (descriptive)
Future – heads up X hours before patient deteriorates (predictive)
Recommend an action based on future event – predicting a problem and advising what is (and perhaps in the future, doing automatically) the best action to prevent it from happening. Patient is developing hypovolemic shock, give fluids to prevent that (Prescriptive).
2. Types of technology approaches and required data
Although it seems that every company in the field is “utilizing AI” there is actually a spectrum of technological approaches applicable for such tasks. By large it can be static role-based algorithms (summarizing a ground truth from the public domain with or without in-house experts organizing it) to simple ML (logistic regression) to more sophisticated but still fairly straightforward ML (SVM or gradient boosting trees) to more complex models like DL (CNNs, RNNs) or reinforcement learning.
Each of these of approaches has pros / cons that can facilitate an entire post. I’ll just stress out two notions – (1) the more complex is the model, the more data it requires and (2) simplicity isn’t necessarily a bad thing 😊 (both per model explainability and performance as several studies demonstrated that there is only a minor difference in the performance of ANNs and logistic regression…)
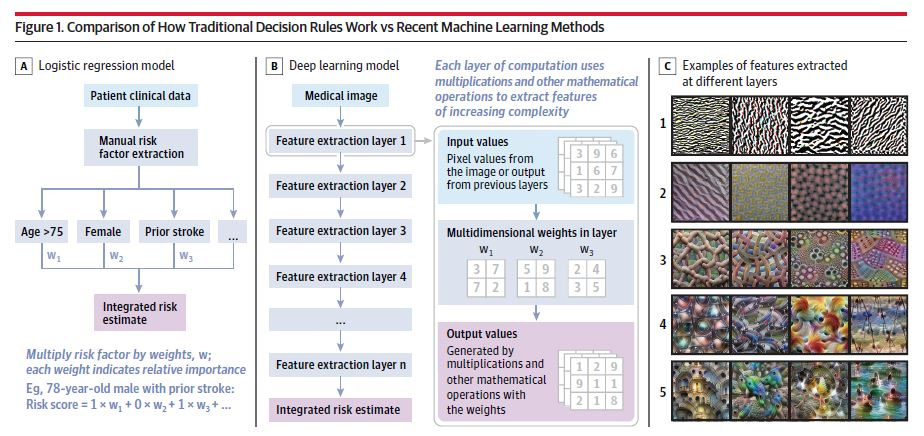
3. Workflow integration and type of intervention
AI Models need to be embedded into a delivery mechanism and incorporated into an existing or altered workflow (in other words transforming the model into a product). This aspect is not limited to data or software architecture (tapping into the production servers, ‘convincing’ the EHR vendor and/or administration team to add your “insights” as an integral part) but also to human behavior (what type of recommendation is given – assistive vs. directive, how do you present the recommendation) and change management (who is responsible and for what, how the current process is altered).
Why AI-driven DSS tools are still not a prevalent modality
Quoting the aforementioned meta-analysis on image-based COVID prediction models (2,212 models with zero “ready for clinical use”) -
"Despite the huge efforts of researchers to develop machine learning models for COVID-19 diagnosis and prognosis, we found methodological flaws and many biases throughout the literature, leading to highly optimistic reported performance…” , “…Many were hampered by low-quality data, and in particular the high likelihood of duplicated images across different sources that result in so-called "Frankenstein datasets…"
Let’s try to map some of the key reasons why introducing such tools into the workflows is so challenging:
Training sets and design partnerships vs. real life
In most development processes of AI models, retrospective observational data is used. To a large extent it is far from being truly longitudinal (capturing only a snapshot of the care journey) due to the fragmentation of the healthcare industry. Additionally, vast majority of models are initially developed on a single data set (although data becomes a commodity it is still fairly expensive). And on top of all, medical data is REALLY messy (try to write a patient note in the middle of a night shift and you’ll understand why each disease has dozens of different definitions or why there are some many different ways to define the same outcome… )
Now think about the task the computer is given here. Try to learn from a history that has a lot of censored and disheveled information plus many blind spots, from a specific population and give us a recommendation for another population. Hmmm. One does not need to be a computer expert to understand there is an inherent problem with such task.
First and foremost, this situation can lead to the wrong conclusions (patients administered at hour X are less prone to Y), namely – garbage-in, garbage-out. That’s especially true in the case of rare outcomes that aren’t so rare in healthcare.
Moreover, imbalanced data sets and overfitting can happen (when a very large single data set with large amount of variables is used, the model perfectly fits data to available parameters but not in a way that has any relationship to the clinical outcome that is being modeled).
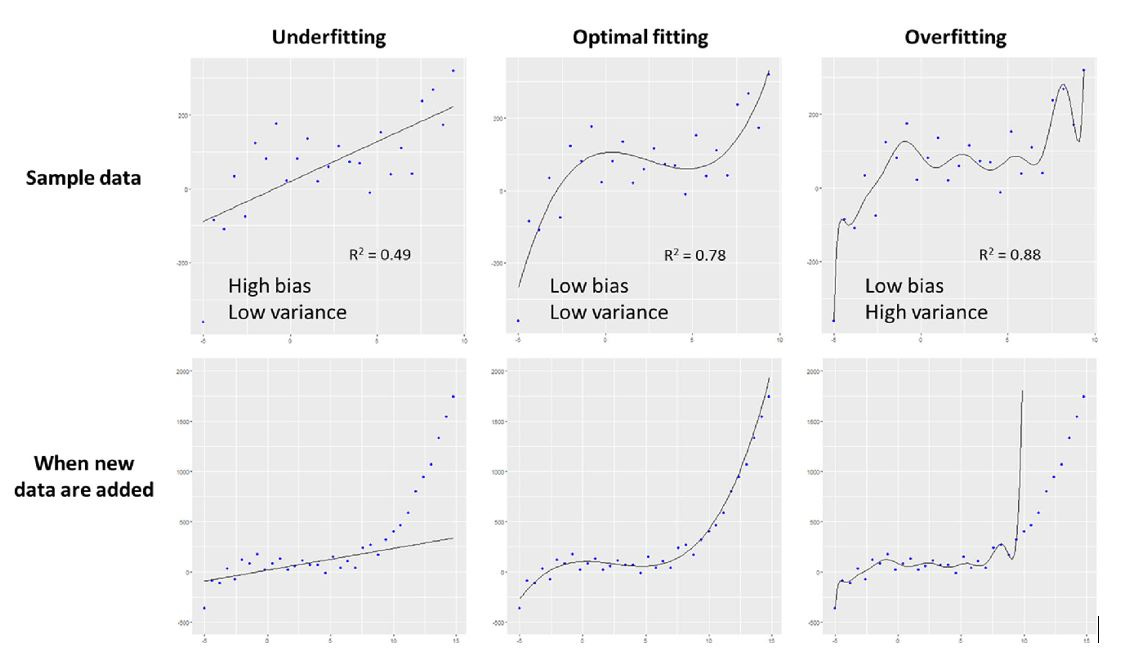
And finally, you reach the problem of bias and lack of generalization.
Because computers can’t (yet) determine if a data set truly represent the target population (race, gender, ethnic groups, tendencies, social support, etc.) the model can reach a perfectly good conclusion for the development population but wrong for others. A good example might be the multi-million dollars failure of IBM’s Watson, who essentially partnered with the crème de la crème of oncology institutions (MD Anderson, Memorial Sloan Kettering, etc.) to develop decision support tools for oncologists. The only thing is that the common patient in this centers is not the general oncology patient elsewhere (high socioeconomic, white vs. well… everyone else).
In other words, you must have a training set that truly represent the target population. There are tools to determine if that’s indeed the case (such as propensity scores matching) but in essence, the more heterogenic your data set is, the better. And external validation is CRUCIAL.
Also, there are emerging ways to converge data from multiple sites in parallel, such as federated learning (FL) environments, and thus addressing these issues. For example, in the EXAM study, 20 leading institutes collaborated via FL and jointly developed a prediction model for future oxygen requirement of COVID-19 patients, based on EHR and image data. Notably, entire on-boarding took only few weeks and it was resulted in a model that generalized across heterogeneous, unharmonized datasets.
Scientific proof
Before taking a drug to a clinical trial a rigorous pre-clinical evaluation is done. By large there it is an identical process for each drug and success metrics are well agreed. Same is true for medical devices. But because SaMD is still a new concept, there is still no unified criteria (i.e. rigorous and transparent) to evaluate performance and reproducibility in a way that will convince health system to embark on the notorious journey of “IT integration”. Even the current performance indicators (discrimination, calibration) are often not sufficiently addressed by developers. (i.e. there is a very large universe of possibilities going beyond the phrase “this model has 95% accuracy…)

Couple of good papers that can add more color –
Challenges to the Reproducibility of Machine Learning Models in Health Care,
Digital health: a path to validation
How to Read Articles That Use Machine Learning Users’ Guides to the Medical Literature
Evaluating the impact of prediction models: lessons learned, challenges, and recommendations
Lastly, as of all of these indicators are targeted to assess the performance of the prediction model itself, they are not even a surrogate to the real questions – what will be the consequences of the intervention. Prof. Nigam Shah from Stanford well describes this issue:
“…none of the measures address the purpose of the model or what matters most to patients, ie, that a classification or prediction from the model results in a favorable change in their care. Given a model’s prediction, whether actions are taken and the effect those actions may have is determined by numerous factors in the health care system. These include a clinician’s capacity to formulate a responsive action, weigh its risks and benefits, and execute the action, as well as the patient’s adherence with the clinical action recommended…”
“…Above all, Evidence is still lacking that deployment of prediction models has improved care and patient outcomes…”
Similar notion (“This systematic review found only sparse evidence that the use of ML-based CDSSs is associated with improved clinician diagnostic performance”) is also found in this paper from JAMA -
The path from Pilot and on-boarding to deployment and utilization
Now, given the lack of widely accepted pre-clinical (in-silico) evaluation process, combined with exceedingly busy healthcare workforce, past over-promises and over-selling related to software in healthcare that resulted mostly in additional work (EHRs….) and the toping of the cake, IT integration, just imagine how challenging it is to convenience a random CIO to test drive a new AI-based tool…
At Clalit we had only two EHR systems (one for in-hospital and one for community care and they are connected) for the entire 4.5M members / 14 hospitals and >1500 clinics. Each new product we even piloted was SUPER challenging and felt like a really bumpy Via Dolorosa.
Workflows are complex mazes that differ between sites, even within the same health systems. It is nonlogic assembly that in most cases articulate around intangible arts (lessons learned by the veterans and passed along) with many different stakeholders involved (physicians, nurses, non-clinical staff, front desk, management, and IT are just some examples).
Consequently, it is critical to understand how exactly a specific solution will be incorporated and what are the downstream consequences that the site should be prepared for. To that extent, having pre-pilot (and by all means pre-deployment) buy-in from ALL relevant stakeholders is crucial.
And now think about doing that at scale…
“…One should realize that introducing a prediction model with subsequent management actions is an introduction of a complex intervention. The entire intervention consists of multiple components that interact: the accuracy of the model predictions, physician and patient understanding of probabilities, expected therapeutic effects of administered treatments, and adherence to predicted probabilities and administered treatments. Consequently, the effects of the model use on downstream patient outcomes are not simply the sum of the consecutive components…”
From a different angle, essentially all AI-models come with a blurry promise – first the customer will add something on top of the current process (i.e. extra costs and overhead!) and sometime in the foreseeable future this effort will result in better quality and / or cost structure… In other words, you are asking for a leap of faith from a system with a razor-thin margin and constant shortage of staff.
Companies too often fail to shorten this time frame or reduce enough the effort needed from the customer. Trying to tackle the other part of the equation (illuminate the fruits of this endeavor) is also super challenging because even after a pilot was done, it is hard to measure the direct outcome both on the administrative / cost side and especially on the clinical side.
The medical staff buy-in
On top of everything, you need to convince the staff that walking this extra mile plus relying on this non-human (competitor?) is worthwhile. Remember that the first line in Hippocrates Oath is “Primum non nocere” (first, do no harm). Physicians are conservatives by default. And currently tired of failed promises of immature solutions. And generally tired. REALLY tired.
Another dashboard or pop-up warning is the last thing a typical physician wants. Alert fatigue and burn-out are strong de-motivators. Fabulous solutions were crafted to counter-attack these attempts.

To conclude, this is an extreme version of different types of buyers (technology, business, clinical) and all are equally important. Too often companies blend or confuse between the different buyers and when losing one, they lose the entire process.
What can / needs to be done (opportunity alert!)
Data heterogeneity - Multisite development and validation process
Creating a diverse development data set composed by different sources (and populations) can vastly reduce the risk of bias and increase the generalizability of a model.
“…Models developed for diagnosis and prognostication from radiological imaging data are limited by the quality of their training data. While many public datasets exist for researchers to train deep learning models for these purposes, we have determined that these datasets are not large enough, or of suitable quality, to train reliable models, and all studies using publicly available datasets exhibit a high or unclear risk of bias…”
The integration between different data sets along with data cleansing, normalization within a secure environment is far from being an easy task. However, these are the corner stones for the development process and could worth their weight in gold. ~80% of “AI” is about organizing the data and arguably much harder (and limiting) than the prediction algorithms that follow.
External validation is a must. This is the developers’ sanity check and one can’t stress enough how important it is to make it as real as possible. To that extent I would argue that using the same data set and splitting it to a development set and a validation set is simply not good enough. That’s why it’s called external. “What is difficult in training will become easy in battle” is a cliché, but highly relevant here.
On that note, it is important to pay attention to the emerging AI/ML based SaMD regulation coming from the FDA and the notion of dynamic monitoring required by vendors.
“…manufacturers would be expected to commit to the principles of transparency and real-world performance monitoring for AI/ML-based SaMD. FDA would also expect the manufacturer to provide periodic reporting to FDA on updates that were implemented as part of the approved SPS and ACP, as well as performance metrics for those SaMD…”
In other words, the FDA will request to execute cycles of validation. At scale. Ouch.
Solutions to such tasks are only starting to emerge. One example is Rhino Health (Arkin portfolio company) that offer multi-site dynamic AI workshop based on Federated Learning (‘Continuous Distributed Learning’).
Rhino’s solution essentially enables developers to work in parallel with multiple hospitals in real time to refine, validate, monitor and improve the performance of their AI models. Another huge benefit for this approach is having a single pre-deployment process for an entire health system (or consortium). In simple words, HCA can deploy an AI product in merely a few weeks to all of its 186 hospitals.
The Exam study that was previously mentioned (20 leading sites worldwide using Federated Learning for COVID-19 related prediction model) was a proof of concept for Rhino’s approach and led by their CEO and Co-Founder Dr. Ittai Dayan.
Recommendation heterogeneity and Explainability
AI-black box problem has long been discussed. Nevertheless, it is far from being solved. I would argue that in many cases introducing AI-based tools is a psychological rather than a technological challenge.
Clinicians appreciate interpretable predictions. Even mitigating this gap can mean a great deal. Some nice approaches are showcasing which features most influenced the model, hit (saliency) maps on images to indicate which regions influenced the model (great examples in digital pathology) and presenting the biological reasoning (this patient is going to develop acute kidney injury because his urine output is low, his electrolytes are imbalanced, etc.)
Also, providing a level of confidence can be helpful to emulate a discussion with a fellow colleague, weighing pros and cons for a given action. Most cases in medicine are far from 100% certain, black and white decisions. Front-end developers most think how to better communicate the product recommendations.
In that respect, a nice article was recently published in Nature, trying to better understand how physicians responds to different sources of recommendations (human expert vs. AI)
Team and product heterogeneity
As previously discussed, introducing a new provider or payors facing AI-model is a combination between a business, clinical and technological problem. As such, IMO heterogeneous teams, with complementary expertise from different domains is not a nice feature but almost a prerequisite. Workflows are complex and changing them is hard. A wider toolbox can help. An extension to this argument is products combining service and tech. I touched on this notion in another post and it is super relevant in this case (and I guess in digital health in general) as well. On-boarding and deployment are always longer and more complex than expected and health system don’t have sufficient resources (manpower, knowledge). Trimming them into a frictionless as possible process could differ between scaling a product and a dead end. It is impossible without boots on the ground. The million (or billion) dollar question is how to make this process scalable and reliable.

LinkedIn: https://www.linkedin.com/in/nadav-shimoni-m-d-03992489/
Twitter: @Nadav_Shimoni
If you liked this post, you can easily share it here -
Want these posts instantly in your mailbox?